The Fastest Way to Aggregate API Data — Visually in Unmeshed
Aggregating data from multiple services is a routine part of building modern applications—but for developers, it’s anything but simple. Stitching together API calls means writing repetitive glue code, handling retries and edge cases and manually parsing responses just to deliver a single JSON.
Even when services are unrelated, they often run sequentially, adding hundreds of milliseconds in latency that hurt frontend performance. Worse yet, adding secret management is such a hassle and duplicate inconsistent logic across teams, quickly making a simple data aggregation a frustrating time sink.
Even more challenging, once deployed, these flows are locked in. Need to trace a failure or tweak the logic? That usually means digging through logs and redeploying code. There’s no visibility, no flexibility, and no easy way to optimize. Developers are stuck maintaining orchestration scaffolding instead of focusing on business logic.
That’s the pain Unmeshed was built to eliminate—turning complex, fragile workflows into streamlined, visual flows that run faster, safer, and smarter. No glue code. No redeploys. Just results.
In this post, we’ll walk through a real-world use case where we aggregate data from three backend services, first by calling them sequentially, then optimizing them to run in parallel—all with zero code changes to the backend, as demonstrate in our platform.
Use Case: Aggregating Product Info from 3 APIs
Let's say you're building a storefront experience and need to pull together three types of data for a given product:
- Customer Reviews
GET/api/reviews?skuId=SKU_ID
- Recently Purchased
GET/api/recent?skuId=SKU_ID
- You May Also Like (YMAL)
GET/api/ymal?skuId=SKU_ID
Each of these endpoints is secured using an API key stored in Unmeshed secrets (secrets.api_key_product), and each requires a query parameter: SKU Id.
Here, we want to aggregate the responses into the following structure:
{
"reviews": { ... },
"recent": { ... },
"youMayAlsoLike": { ... }
}Step 1: Creating the Aggregation Workflow in Unmeshed Platform:
We begin by creating a new flow in the UI:
-
Click Add Flow
-
Name it something like "Demo - API Aggregation"
Then, we add three HTTP tasks, one for each endpoint.
Configuring the "Reviews" Step
-
Endpoint:
https://storefront-demo-api.unmeshed.com/api/reviews -
Params: skuId =
{{context.input.skuId}} -
Headers: Authorization =
{{secrets.api_key_product}}
We test the step by providing a sample input skuId. If it fails (as it did in our walkthrough), we simply fix the input and rerun the test.
Once successful, we repeat the same configuration for the other two endpoints: recent and YMAL. The structure and secrets are reused; only the endpoints change.
Step 2: Shaping the Output with a JavaScript Task
Once all three API calls are defined, we use a JavaScript step to merge their responses into the desired format.
In the JS task, we refer the output of each API task and assign it to its corresponding key:
return {
reviews: steps.reviews.response.body,
recent: steps.recent.response.body,
youMayAlsoLike: steps.ymal.response.body,
};Now, the workflow returns a single, clean, aggregated response that's ready for your frontend.
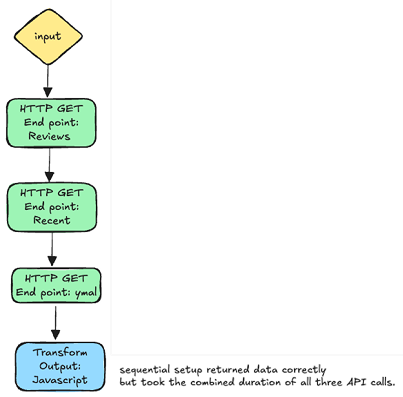
Step 3: Sequential = Simple but Slower
At this point, we have three tasks configured in sequence. While this works, it means each API must wait for the previous one to finish--leading to slower total execution time.
In our test, this sequential setup returned data correctly but took the combined duration of all three API calls.
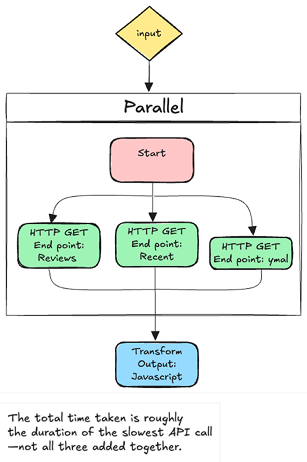
Step 4: Optimizing with Parallel Execution
Here's where Unmeshed orchestration flexibility shines.
We converted our workflow from sequential to parallel execution with a simple drag-and-drop:
-
Insert a Parallel step
-
Drag the three API tasks into it
Now, all three API calls run concurrently. The total time taken is roughly the duration of the slowest API call--not all three added together.
In our test, the performance improvement was immediately noticeable.
API Data Aggregation in Unmeshed: From Sequential to Parallel in Minutes
Unmeshed lets you orchestrate external services with zero code, and restructure execution plans on the fly. That means:
-
Drag-and-drop orchestration of API calls
-
Instantly switch from sequential to parallel -- no backend code changes
-
Built-in JavaScript task to shape response JSON
-
Secure secret injection without hardcoding
-
Visual timeline to debug and trace performance
-
Reusable patterns across teams
We've recorded a full walkthrough of this use case, showing exactly how to build, test, and optimize this API aggregation flow. 👉 Watch the video here
Final thought
By demonstrating our developer-centric orchestration platform that makes it easy to compose and optimize workflows, we promise that you'll get:
-
Built-in secrets management
-
A visual builder for parallel/conditional logic
-
SDKs for integrating your services instantly
Want to try this for your own APIs? Sign up Get Started with Unmeshed and build your first flow in under 5 minutes or find us in Microsoft Azure Marketplace.


