Telecom Order Fulfillment Orchestration at Scale | Unmeshed
We demonstrate a telecom order fulfillment workflow and shows why the problem is less about connecting systems and more about coordinating processes.
The telecom industry has some of the most complex and distributed systems out there. Over time, business logic gets stitched together in whatever way makes sense at the time. Some parts become event-driven through pub/sub, some stay as direct API calls and state gets tracked across different databases.
In a typical telecom environment, you are dealing with modern microservices, legacy OSS/BSS platforms, and third-party integrations. Each system owns a small part of the overall workflow. If you want a deeper dive into OSS/BSS fundamentals, Ericsson has a good reference.
This setup works when things are simple. But once workflows become long-running, stateful, and spread across many systems, it becomes harder to manage. Durability gets questionable and scaling gets harder. Soon enough, no one has a clear end-to-end picture.
Instead of getting into every telecom-specific detail, we will use an order fulfillment workflow to show how these pieces can be brought together into one coherent process. The goal is to show how Unmeshed can act as the orchestration layer that connects systems, keeping the workflow visible. While this example is based on telecom, the same business logic applies to any industry dealing with complex and distributed workflows.
System Requirements For Scalable Telecom Orchestration
For this kind of workflow, the system needs to remember where each order is and be able to resume after failures. It also needs to avoid duplicate execution and show the status (completed, pending or blocked).
With Unmeshed, independent steps like data fetches and validations can run in parallel. Teams can also build human-in-the-loop flows by pausing for approvals, routing tasks to the right people, and resuming the workflow without breaking the overall process. A mature orchestration platform should handle retries, timeouts, partial failures, and pause-and-resume behavior while preventing duplicate or conflicting execution through identifiers like order IDs.
As the workload scales, teams spend less time worrying about performance and SLAs while still supporting both API-driven and event-driven workflows. They should also retain a complete audit trail of every action and decision across the process.
Use Case: Designing an Order Fulfillment Workflow
Telecom order fulfillment appears simple on the surface. A user selects a plan and chooses a device and places an order. In practice this initiates a multi-stage workflow that spans customer systems network provisioning inventory management billing and external integrations. Each stage introduces its own challenges and processes can run into failures latency-related issues and data dependencies which makes the workflow both distributed and stateful.
Now there are a few ways you could build something like this.
One approach is chaining API calls together. It starts with the frontend calling one service which calls another which calls another. It is simple but once you introduce things like waiting for instance giving the buyer a 24-hour waiting period while the cart remains open it starts to become awkward and increases the risk of partial or full failures. Eventually it gets messy, the state gets scattered across services and it becomes harder to know what is actually going on.
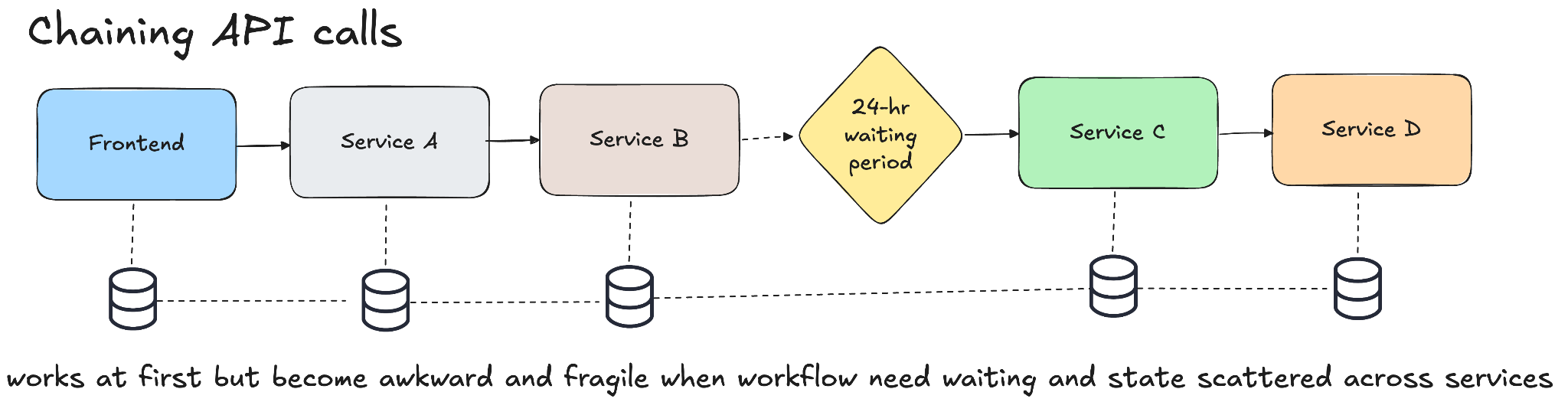
Another approach is to rely heavily on event-driven systems where you publish events, let different services react and store state in databases.
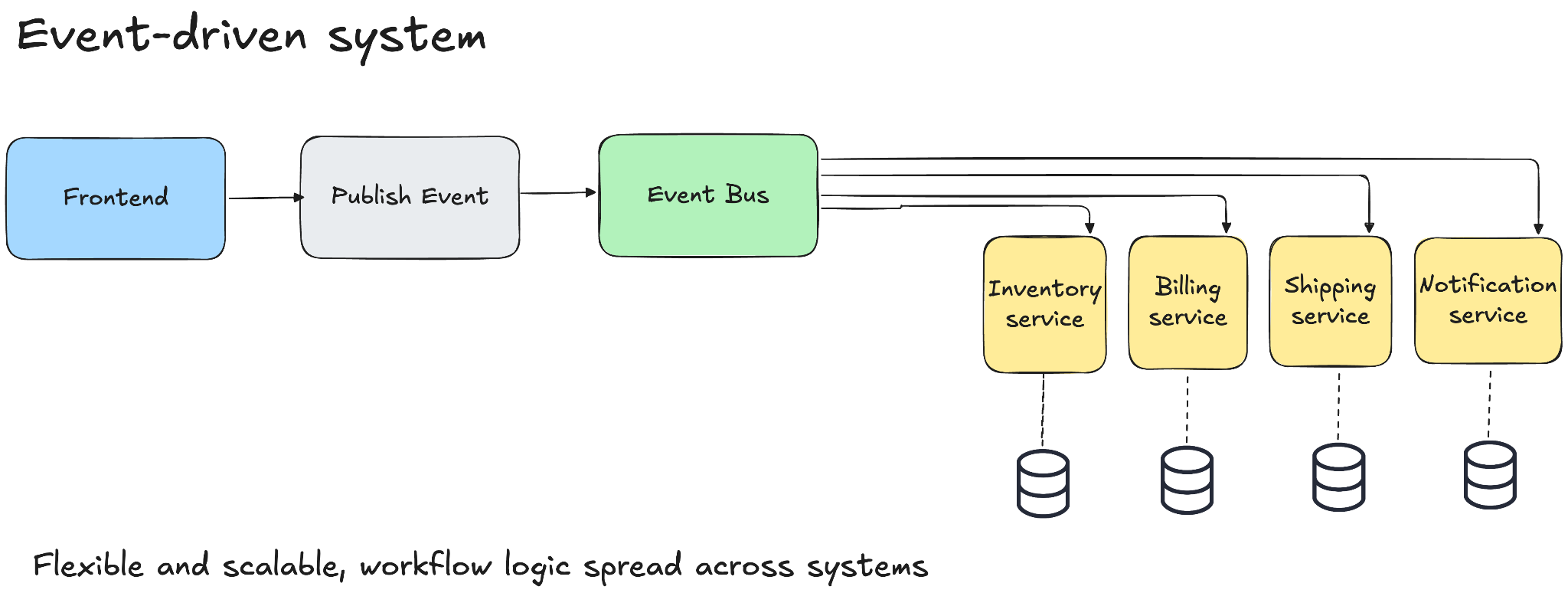
This is more flexible and scalable but the downside is that your workflow logic is spread across multiple systems and teams. Because of the lack of visibility debugging becomes painful and something as simple as “where is this order stuck?” turns into a multi-hour investigation.
Workflow in Action - Inside Unmeshed Platform
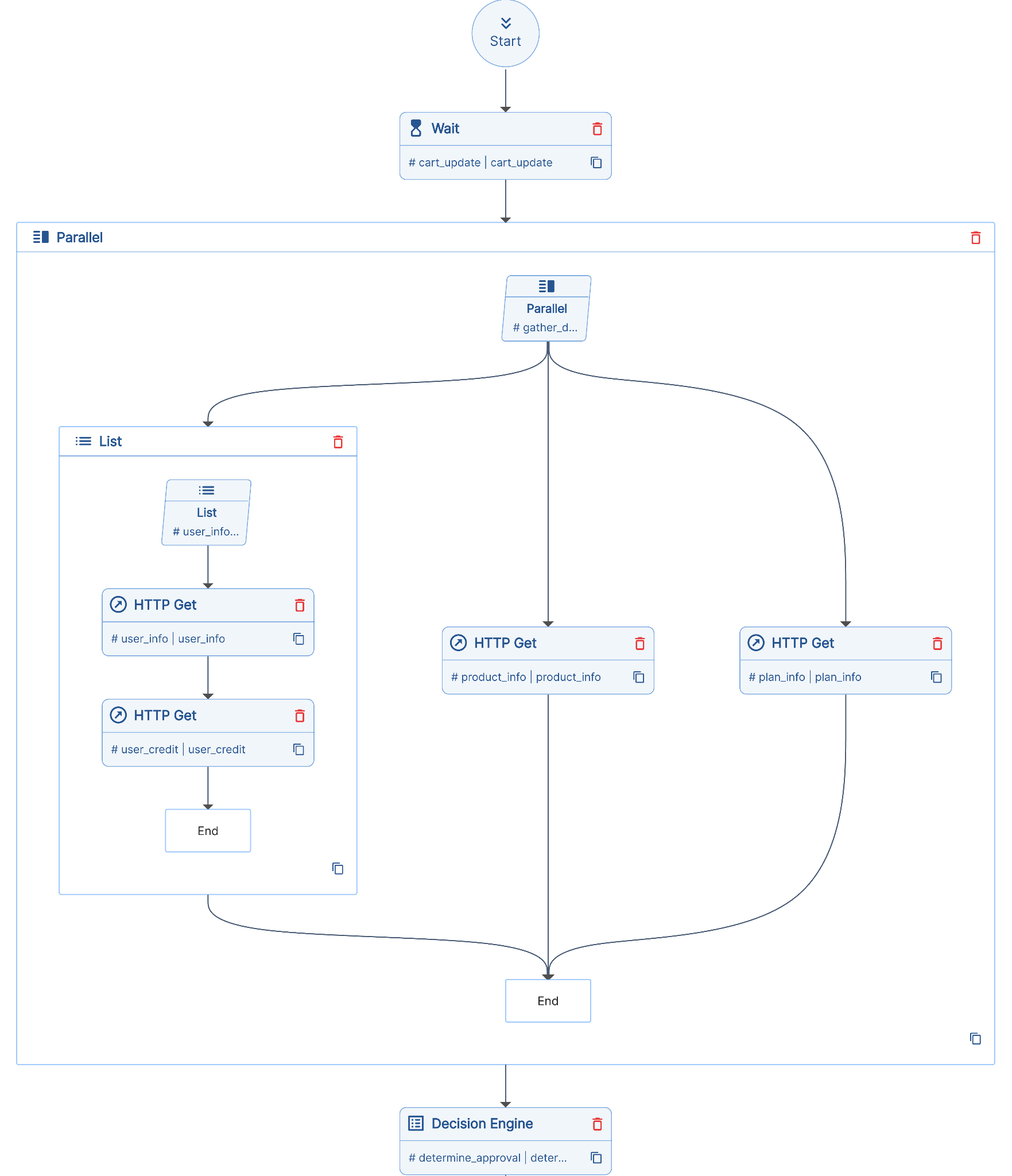
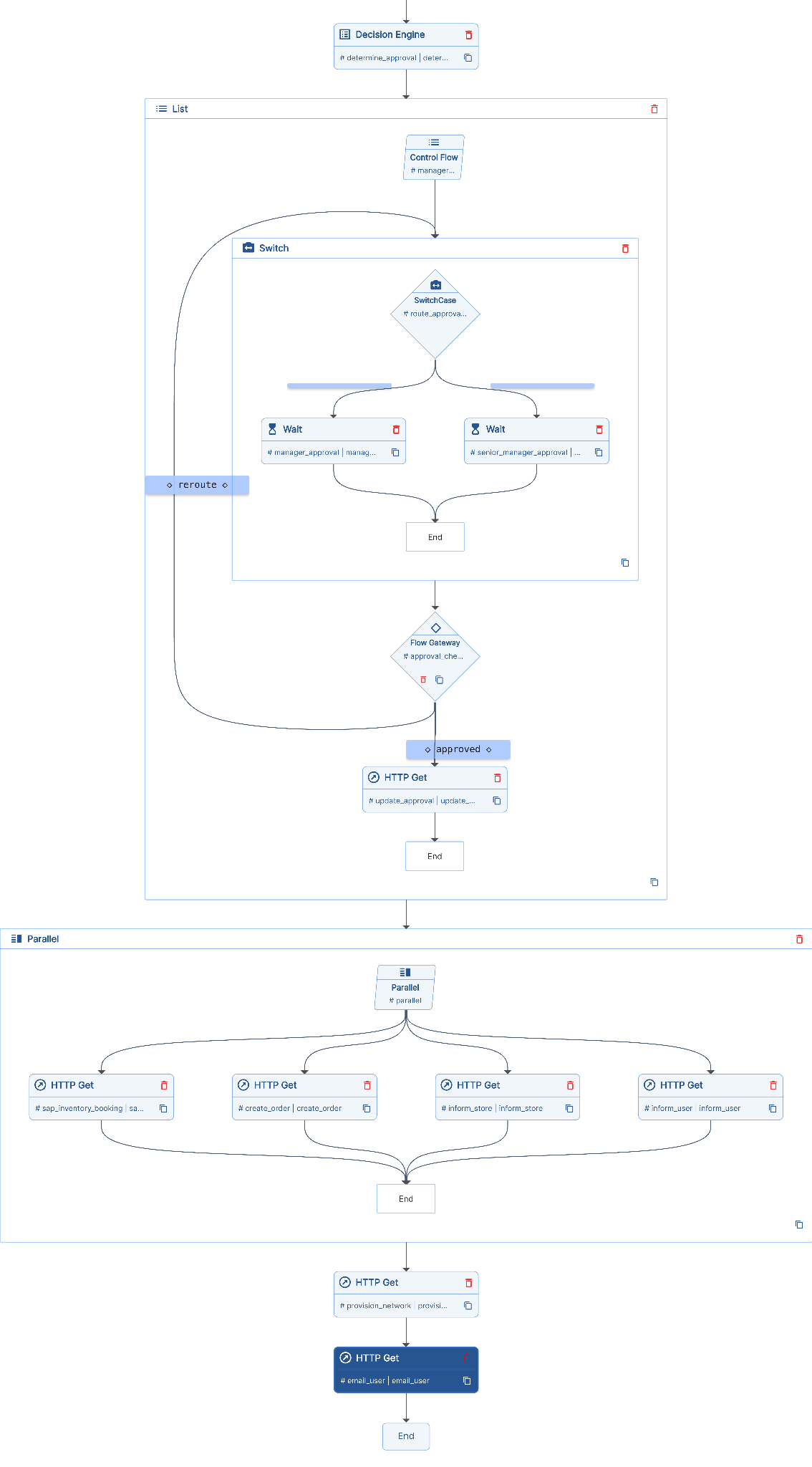
Here, Unmeshed coordinates workflow, from the moment a user initiates an order. Instead of letting workflow logic live everywhere we model it as a Process Definition in Unmeshed. The first thing we do is wait for the cart to be finalized. This might sound trivial but it actually is not because we need to hold the state for potentially hours.
In this workflow we model this as a Wait step with a pause of up to 24 hours. At times updates like adding a phone or changing a plan come in via APIs and update the same workflow instance. If the user fails to complete the purchase the workflow is either closed or a reminder email is sent. This is noticeably hard to do cleanly with just APIs or pub/sub.
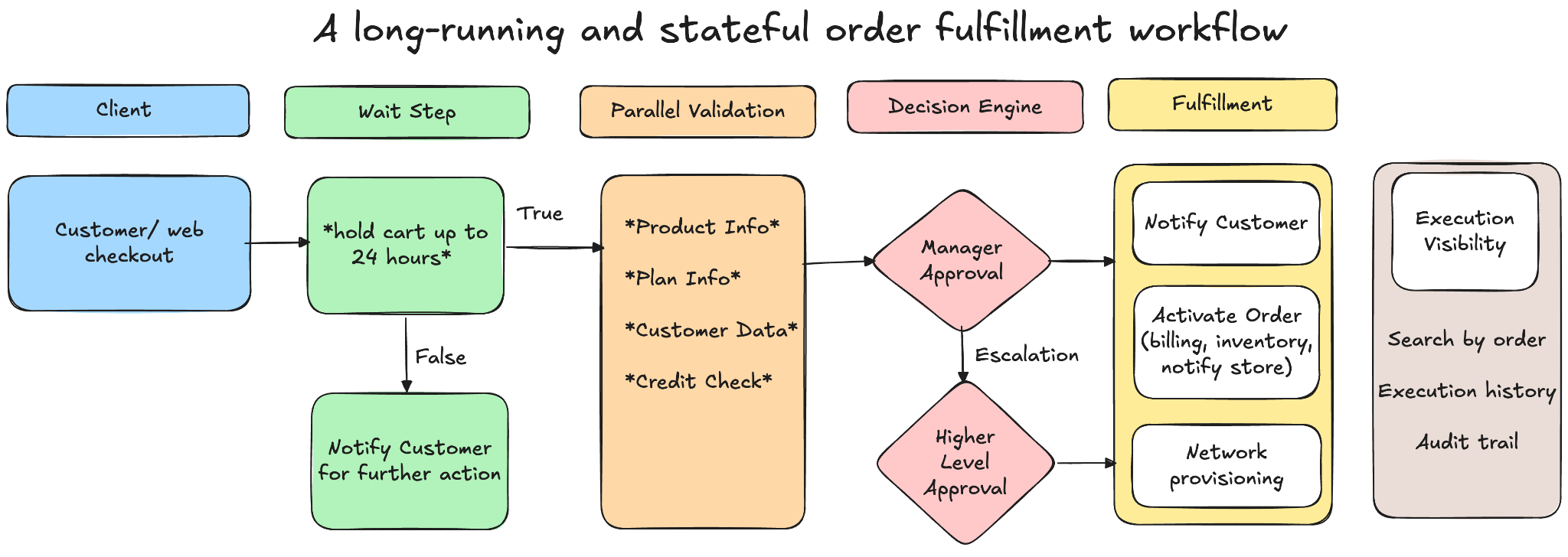
Once the user checks out that is where things get interesting.
Coordinate Parallel Work and Decision Table
At this point a sequential workflow is not the most practical method because it increases the latency of the workflow. We model this using the Parallel step in Unmeshed where multiple independent steps can run in parallel such as fetching product details validating the plan pulling user data and running a credit check. Based on the output of all those steps we need to decide what to do next. For example, does this order require manager approval? Instead of hardcoding this logic we push it into the Decision Table so business rules can evolve without rewriting code.
Once we know the approval level we bring in a Human-in-the-loop step. The workflow pauses and routes the task to the appropriate queue. If a manager cannot approve it they can escalate it to another approver and the workflow simply loops back and re-routes accordingly.
From Approval to Fulfillment
Now comes the non-trivial part of the entire workflow. We need the system to pause, resume and reroute without losing state or duplicating work. Once the approval is completed we move into fulfillment and this is where multiple backend systems come into play.
- Reserve inventory for the phone
- Create an order in a retail or fulfillment system
- Notify the store
- Update CRM and billing systems
- Trigger network provisioning to activate the line
Each of these is modeled as an HTTP step or integration step in Unmeshed. Failures happen in the real world and anything that could potentially happen probably will at some point, but we will not spend too much time explaining all of them here.
Why Workflow Visibility Matters at Scale
At a small scale almost anything works. As you scale anything can happen and everything breaks in interesting ways. Workflows run for hours or days, systems go down, traffic spikes happen and requirements change mid-flight.
Without orchestration you usually end up handling retries, rollbacks and partial failures across multiple services yourself. With orchestration, all of these can be automated much more easily because they live in one place which is the workflow.
Visibility matters at this point because it stops you from making wild guesses about how the system failed and frantically trying to locate where it failed. Every time this workflow runs Unmeshed keeps a full execution history. So if a client calls and asks “What happened to my order?” we could literally pull up the workflow using an order ID and see:
- Which steps ran
- What data each step received
- Where it failed if it failed
- What decisions were made
That level of visibility is almost impossible when logic is spread across systems.
Bringing It Together
Telecom order fulfillment is not just about connecting systems. At some point, it becomes about coordinating what happens across them.
Once approvals, retries, failures, and long-running states come in, you need to know where the order is and what should happen next. That is the part orchestration helps with. Instead of spreading that logic across services, you keep the flow in one place and let each system do its own job.
If you have workflows like this, try modeling one in Unmeshed and see whether it feels cleaner.


